This is a small tutorial on how to improve the performance of MySQL queries by using partitioning.
As a Data Engineer, I frequently come across issues where the response time of APIs is very poor or some ETL pipeline is taking time. So as a part of improving the performance of the systems which use MySQL as database, I use partitioning as one of the basic optimization steps.
In this article, I am going to show the performance difference between a partitioned table and a non-partitioned table by running a simple query.
Setup
I am using a local MySQL server, MySQL workbench, and salaries table from the sample employee data. You can also download the dumps of the salaries table’s sample data from here.
What is Partitioning?
MySQL is a Relational Database Management System (RDBMS) which stores data in the form of rows and columns in a table.
Different DB engine stores table data in the file systems in such a way, if you run a simple filter query on a table it will scan the whole file in which table data is stored.
Partitioning a table divides the data into logical chunks based on keys(columns values) and stores the chunks inside the file system in such a way, if a simple filter query is run on the partitioned table it will only scan the file containing a chunk of data that you required.
So in a way partitioning distributes your table’s data across the file system, so when the query is run on a table only a fraction of data is processed which results in better performance.
Let’s take an example
Data in our salaries table looks like this:
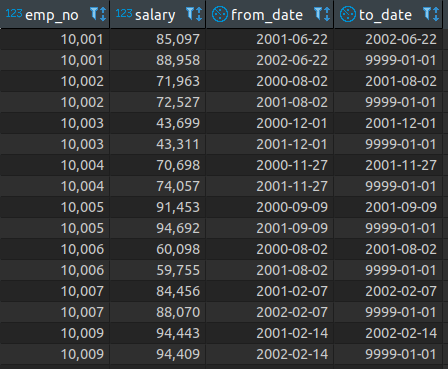
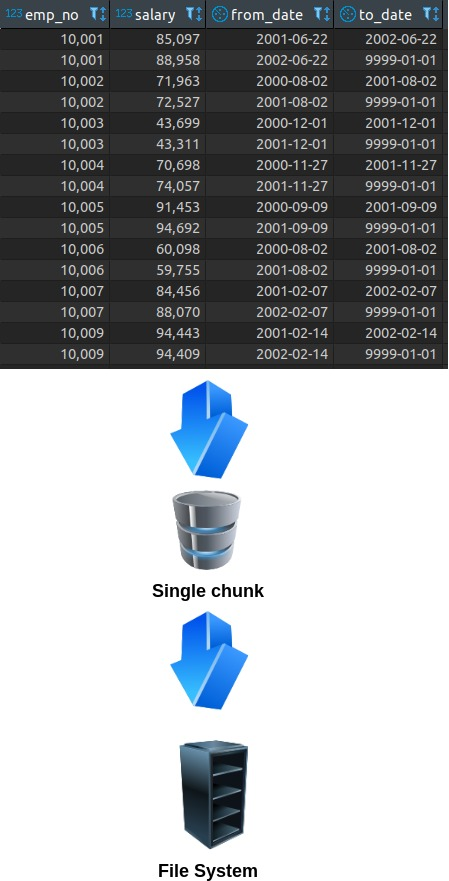
By default, this data is stored in a single chunk inside the file system.
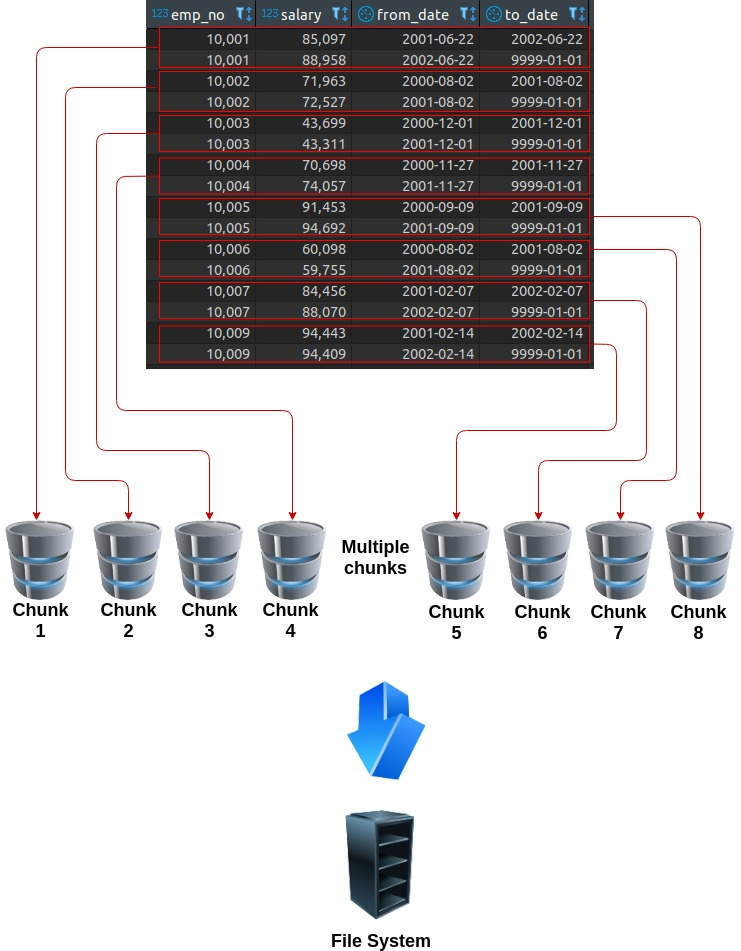
If we partition the table by taking “emp_no” columns as key the data will be stored in multiple chunks based on number of partitions:
Now we understand how partitioning works let’s start testing this feature and find the difference in the run time of SQL queries with and without partitions.
Implementation
We will use the below simple query for testing:
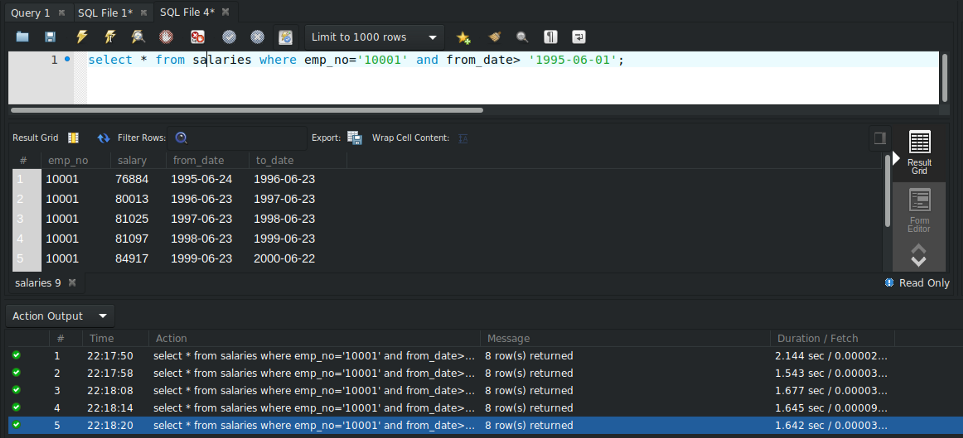
SELECT * FROM salaries WHERE emp_no='10001' AND from_date> '1995–06–01';I have run this query multiple times as shown below, and the average run time is 1.7302 sec approx.
lets examine how MySQL executes this query using EXPLAIN clause.
EXPLAIN SELECT * FROM salaries WHERE emp_no='10001' AND from_date> '1995–06–01';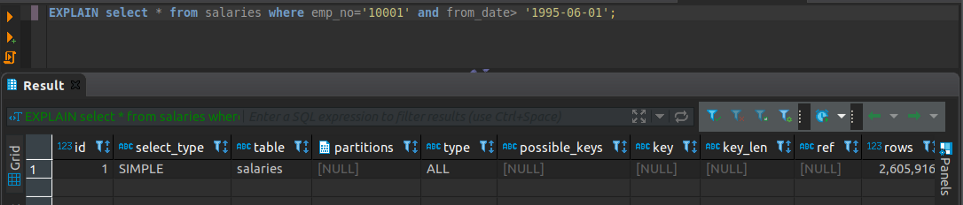
As we can see from the result there are no partitions in this table that is why the “partitions” column has a NULL value.
Let create another table with the same schema.
CREATE TABLE test_salaries LIKE salaries;Now we will create partitions on this table before inserting data.
ALTER TABLE test_salaries PARTITION BY KEY(emp_no) PARTITIONS 100;I am selecting “emp_no” column as a key, in production you should carefully select this key column for better performance.
Ok, now we are ready to run our simple filter query on this partitioned table.
SELECT * FROM test_salaries WHERE emp_no='10001' AND from_date> '1995–06–01';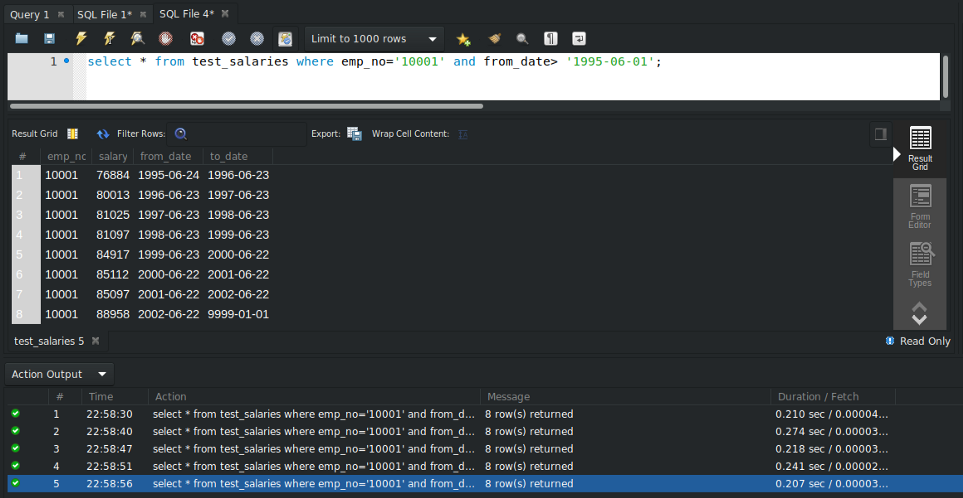
Again I ran this query multiple times as shown above, and the average run time is 0.23 sec approx.
So as we can see there is a significant improvement of the query run time from 1.7302 sec to 0.23 sec.
Once again let’s check how MySQL executes this query in the partitioned table by using EXPLAIN clause.
EXPLAIN SELECT * FROM test_salaries WHERE emp_no=’10001' AND from_date> ‘1995–06–01’;
This time partitions column returns some value in my case it’s p73(Might be different for you).
So what’s actually happening is that MySQL is scanning only one partition (a small chunk of data) which is why the query runs significantly faster than the non-partitioned table.
Conclusion
Partitioning is a powerful optimization technique, which will help you in improving your query performance. In order to properly utilize this technique, it is recommended that first, you analyze your data and properly choose the key columns on which partitioned is to be done, as well as a suitable number of partitions based on the volume of your data.
I hope you like my article, If you want more information on this topic, you can follow and message me on Instagram or LinkedIn.